Hi everyone, hope you’re doing good.
In my last post I explained some basic concepts about Multipath and the importance to use it. You can read more here: Device Mapper Multipath – How this works? Why as a DBA I should concern about it?
On today’s blog post I’ll explain a situation that a client faced regarding a “failure” in a disk.
First of all, let’s summarize about the environment:
- 2 Nodes Cluster running on Oracle Grid Infrastructure 19.21;
- Storage is NetApp, LUNs are provided through iSCSI;
- 5 DiskGroups: GRID1 (for OCR and Voting Disk), DATA (to store the database itself, we also have a ADVM/ACFS for TDE wallet on this diskgroup), REDO1 (to multiplex online redolog and controlfile), REDO2 (to multiplex online redolog and controlfile) and FRA (for archivelogs);
- ASM Disks are managed by ASMLib;
- OS is RHEL 7 (going to be upgraded to RHEL 8 soon);
- Multipath solution is DM Multipath (native on Linux).
Perfect, now, let’s undertand what happened on this client.
I received a call that something wrong was going in a DB.
When I logged in into DB Server, I noticed that even trying to connect to DB using SQL*Plus was hanging.
First thing I did it was to check /var/log/messages:
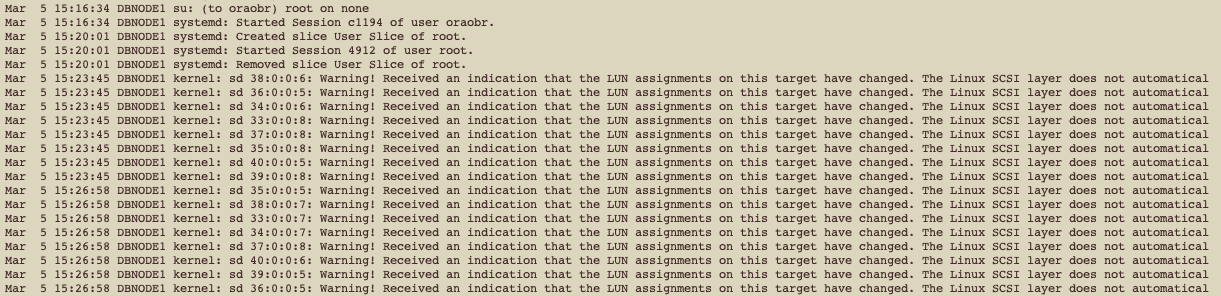
First messages that we saw the ones listed above.
Ok, few minutes later, we have new messages on /var/log/messages:

We can clearly see the we are receiving I/O error for some devices. If you noticed, there are some messages regarding multipath:
Mar 5 16:04:18 DBNODE1 kernel: device-mapper: multipath: Failing path 69:112.
Then, all the paths for a specific device were marked as failed:
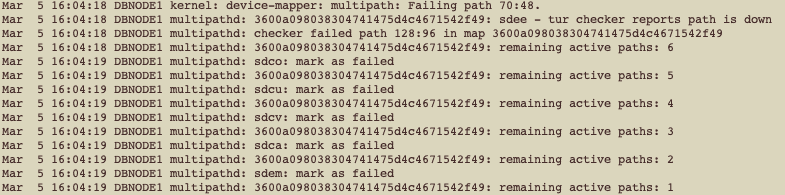
As you can see, all paths were failing until we have no active paths, and then, we got this on /var/log/messages:
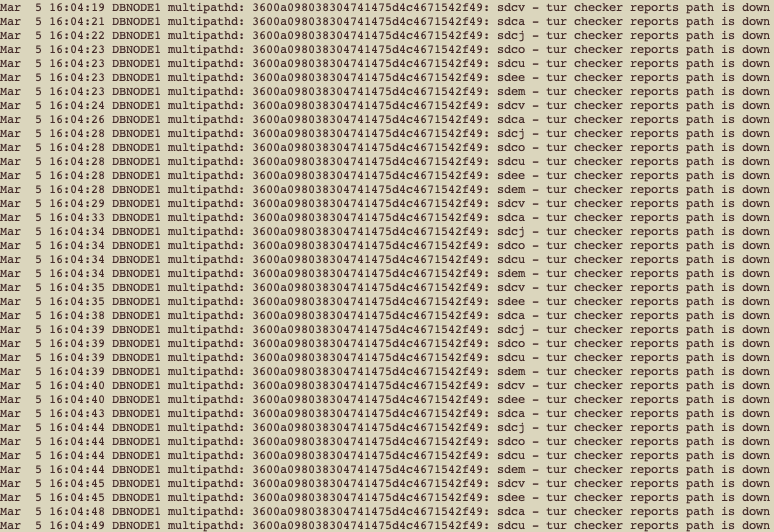
OK, if you observe, we have multiple paths showing as down, but for only one disk/LUN: 3600a098038304741475d4c4671542f49
Time to check more details about this LUN. First, let’s check if we have partitions for this LUN:
lsblk |grep 3600a098038304741475d4c4671542f49
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
If you observe, we have multiple paths, but only one partition. So, the device name for the partitioned device is 3600a098038304741475d4c4671542f49p1.
By default, all multipathed devices are under /dev/mapper directory.
Let’s check if this device is an ASM disk:
/oracle/app/193/grid/bin/kfed read /dev/mapper/3600a098038304741475d4c4671542f49p1 |grep ‘kfdhdb.dskname\|kfdhdb.grpname\|kfdhdb.hdrsts’
kfdhdb.hdrsts: 3 ; 0x027: KFDHDR_MEMBER
kfdhdb.dskname: OBP_DATA_0007 ; 0x028: length=13
kfdhdb.grpname: OBP_DATA_NEW ; 0x048: length=12
OK, this is an ASM disk: OBP_DATA_0007 (kfdhdb.dskname) and is membro (kfdhdb.hdrsts: KFDHDR_MEMBER) of a ASM disk group (kfdhdb.grpname): OBP_DATA_NEW.
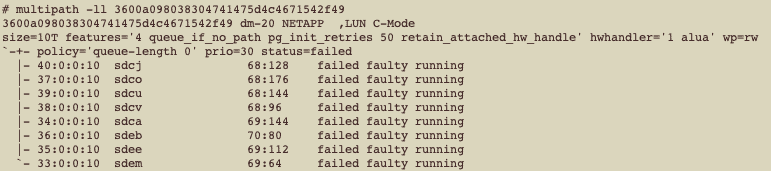
Let’s now check the multipath status for this disk:
multipath -ll 3600a098038304741475d4c4671542f49
600a098038304741475d4c4671542f49 dm-20 NETAPP ,LUN C-Mode
size=10T features=’4 queue_if_no_path pg_init_retries 50 retain_attached_hw_handle’ hwhandler=’1 alua’ wp=rw
`-+- policy=’queue-length 0′ prio=30 status=failed
|- 40:0:0:10 sdcj 68:128 failed faulty running
|- 37:0:0:10 sdco 68:176 failed faulty running
|- 39:0:0:10 sdcu 68:144 failed faulty running
|- 38:0:0:10 sdcv 68:96 failed faulty running
|- 34:0:0:10 sdca 69:144 failed faulty running
|- 36:0:0:10 sdeb 70:80 failed faulty running
|- 35:0:0:10 sdee 69:112 failed faulty running
`- 33:0:0:10 sdem 69:64 failed faulty running
Humm, interesting, isn’t? All the paths failed.
This situation is not common and usually happens when we have issues on SAN (so, it could be storage, storage controllers, network switches, HBAs). But the interesting here is that ONLY this LUN is being reported as failed. If we were facing issues on SAN, most likely ALL LUNs would be reported as failed.
This was driving us crazy.
So, checking on Red Hat support site, I found the following support note:
To access this link you must have an active support contract with Red Hat.
Just to make sure we are clear on this, I will put some useful information here that I got from this support article. The note is very comprehensive and I will only put some pieces for the note:
Root Cause
Storage is notifying the host that a change within the storage configuration (mapping/presentation/masking of luns) has occurred. For example, storage added new luns (benign), unmapped and removed luns not currently in use (benign), unmapped and removed luns currently in use (data loss), or swapped luns (data corruption likely).
Resolution
Discuss and review the changes with your storage admin to determine how to proceed.
Note: if no changes have happened within storage, engage the storage vendor to determine why this hardware status is being returned. The kernel only logs this event returned from storage. The kernel does not have any further insight into why storage is returning this status event to the host.
So, summarizing the one of the possible root causes:
- Notification from storage about some change on LUN (mapping, presentation, masking).
About the resolution, this is interesting:
- The kernel only logs this event returned from the storage.
So, the message “Warning! Received an indication that the LUN assignments on this target have changed.” is exhibited on /var/log/messages but basically is an event returned from the storage only.
As we were facing this issue in a real-time moment, we were able to open a ticket with vendor (NetApp) and have a support engineer with us to discuss about the issue and glad we were able to identify (and understand) why we faced this issue.
This environment is a PrePod environment. We did a refresh a few months ago for this environment cloning the disks from Production. This is a task that we executed lot of times on the client using the same cloning approach and we never faced issues.
So, in a storage solution, we can have disk/storage arrays, which we can call as “aggregates”. So on this client, they have some aggregates. The cloned LUN was being hosted on an AFF aggregate. This means All Flash FAS, and it’s an aggregate that uses SSDs exclusively. Client was facing some space capacity limitation on their AFF aggregate and were moving the PreProd LUNs to a FAS aggregate. FAS means Fabric-Attached Storage, it’s a hybrid storage array, composed by SSDs and Hard Disk Drives.
So, basically, they were moving the LUN (for disk DATA7) from AFF to FAS aggregate.
When storage team explained that they were moving the LUN to another aggregate, the NetApp engineer asked the storage team to check some info. Luckily they saved some info regarding te LUN before the movement.
The command below has been executed from the storage console (NetApp), it maybe could not working depending of the version of the OS you are using on your NetApp storage. Please note that if you have storage from other vendors, the basic concepts probably will be the same, but the commands could be different:
lun mapping show -path /vol/dbnode1_data_new_007_ref2023/DATA7 -vserver CA-PREPROD-SVM -igroup dbnode1_ig
Vserver Name: CA-PREPROD-SVM
LUN Path: /vol/dbnode1_data_new_007_ref2023/DATA7
Volume Name: node1_data_new_007_ref2023
Qtree Name: “”
LUN Name: DATA7
Igroup Name: dbnode1_ig
Igroup OS Type: linux
Igroup Protocol Type: iscsi
LUN ID: 10
Portset Binding Igroup: –
ALUA: true
Initiators: iqn.1994-05.com.redhat:a916a5e59b8c
LUN Node: CA-AFF1-B
Reporting Nodes: CA-AFF1-A, CA-AFF1-B
Perfect, we can see that LUN DATA7 is on node CA-AFF1-B (LUN Node field).
We can also see that there were two Reporting Nodes for this LUN: CA-AFF1-A and CA-AFF1-B.
Great, after the LUN movement from AFF to FAS, let’s see the details about the LUN again:
lun mapping show -path /vol/dbnode1_data_new_007_ref2023/DATA7 -vserver CA-PREPROD-SVM -igroup dbnode1_ig
Vserver Name: CA-PREPROD-SVM
LUN Path: /vol/dbnode1_data_new_007_ref2023/DATA7
Volume Name: dbnode1_data_new_007_ref2023
Qtree Name: “”
LUN Name: DATA7
Igroup Name: dbnode1_ig
Igroup OS Type: linux
Igroup Protocol Type: iscsi
LUN ID: 10
Portset Binding Igroup: –
ALUA: true
Initiators: iqn.1994-05.com.redhat:a916a5e59b8c
LUN Node: CA-FAS1-D
Reporting Nodes: CA-FAS1-C, CA-FAS1-D
Now, we can see that LUN DATA7 is on node CA-FAS1-D (LUN Node field).
We can also see that there are two Reporting Nodes for this LUN: CA-FAS1-C and CA-FAS1-D.
OK, according with NetApp engineer, the message we received initially on OS: “Warning! Received an indication that the LUN assignments on this target have changed.”, is due because the LUN has been moved to another Node, but, the target Node (CA-FAS1-D) was not listed as a Reporting Node in the Reporting Nodes field. So, according with that he said, if you are planning to move your LUN to a Node that is not listed as a Reporting Node, you would first add the target node as a Reporting Node. So, from storage side:
lun mapping add-reporting-nodes -vserver CA-PREPROD-SVM -path /vol/dbnode1_data_new_007_ref2023/DATA7 -igroup dbnode1_ig -nodes CA-FAS1-C CA-FAS1-D
After this, from DB Server (on Linux), execute the following:
/usr/bin/rescan-scsi-bus.sh –a
So, if Storage Team add the new target nodes (for the FAS aggregate) and OS/Linux team rescan the devices from DB Server, even moving the LUN to FAS aggregate, we would not faced any issue with disk becoming unavailable from OS side.
Please note that the command listed above and executed on console storage are here on this blog post only for informational purposes. If you face a similar scenario, you MUST engage the storage team.
The procedure to add the reporting nodes is listed on a KB article from NetApp:
How Selective LUN Mapping (SLM) works
To access this KB you must have access on NetApp support site.
To make the understanding clear, I will put only one line/piece from the above KB here:
For mobility events that move the LUN from one HA pair to another, the two new commands LUN mapping add-reporting-nodes and LUN mapping remove-reporting-nodes, support changing the nodelist.
That’s it!
I hope this blog post helps!
Thank you!
Peace!
Vinicius


