Olá pessoal, espero que estejam bem.
No meu último post, expliquei um pouco os conceitos sobre Multipath e a importância de usá-lo. Você pode ler o post aqui: Device Mapper Multipath – Como isso funciona? Porque como DBA eu preciso me preocupar com isso?
No post de hoje, vou explicar uma situação que aconteceu num cliente sobre uma possível “falha” de disco.
Primeiro de tudo, vamos resumir o ambiente onde o problema aconteceu:
- Cluster de 2 Nós rodando o Oracle Grid Infrastructure 19.21;
- Storage é NetApp, LUNs são fornecidas através de iSCSI;
- 5 DiskGroups: GRID1 (para OCR e Voting Disk), DATA (para armazenar o banco de dados/datafiles, nós também temos um ADVM/ACFS para o wallet de TDE nesse diskgroup), REDO1 (para multiplicar o online redolog e o controlfile), REDO2 (para multiplicar o online redolog e o controlfile) and FRA (para archivelogs);
- ASM Disks são gerenciados usando ASMLib;
- O Sistema Operacional é o RHEL 7 (que será em breve atualizado para o RHEL 8);
- A solução de Multipath é a DM Multipath (nativa no Linux).
Ótimo! Agora, vamos entender o que aconteceu nesse cliente.
Recebi uma chamada que havia algo errado no Banco de Dados.
Quando eu loguei no servidor de BD, eu observei que mesmo tentando usar o SQL*Plus para logar como SYSDBA, estava travando.
Então, realizei uma verificação no log de sistema operacional, o /var/log/messages:
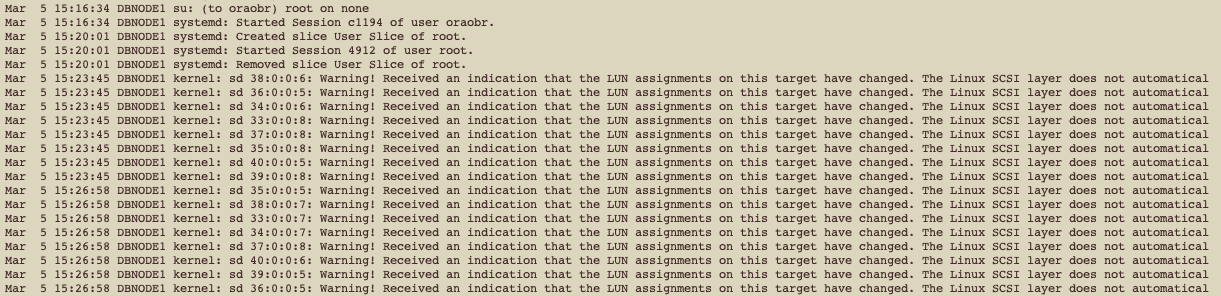
As primeiras mensagens que observamos foram as exibidas acima.
Alguns minutos depois, nós tivemos mais mensagens no /var/log/messages:

Podemos ver claramente que estamos recebendo erros de I/O para alguns dispositivos. Se você observou, há inclusive algumas mensagens à respeito de multipath:
Mar 5 16:04:18 DBNODE1 kernel: device-mapper: multipath: Failing path 69:112.
Então, após isso, todos os paths para um dispositivo específico foram marcados como falha:
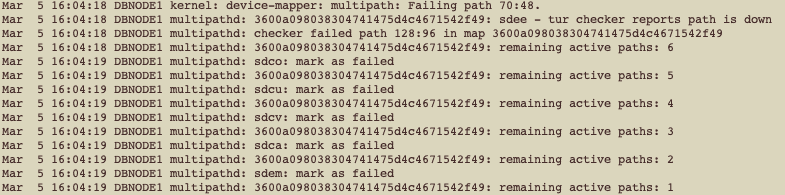
Como podemos ver, todos os paths foram falhando até não termos mais paths ativos para esse dispositivo, nós pegamos isso novamente no /var/log/messages:
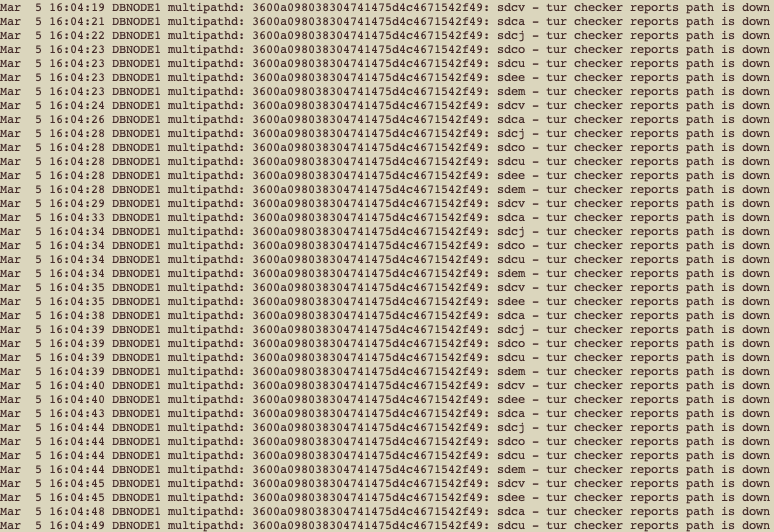
Se você observar bem, nós temos vários paths sendo exibidos como down, mas todos fazem referência a apenas uma LUN: 3600a098038304741475d4c4671542f49
Vamos então checar mais detalhes sobre essa LUN. Vamos primeiro ver se essa LUN possui partições:
lsblk |grep 3600a098038304741475d4c4671542f49
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
└─3600a098038304741475d4c4671542f49 253:20 0 10T 0 mpath
└─3600a098038304741475d4c4671542f49p1 253:24 0 10T 0 part
Se você observar, temos vários paths, mas somente uma partição, o dispositivo com o nome da partição é: 3600a098038304741475d4c4671542f49p1.
Por default, todos os dispositivos de multipath ficam embaixo do diretório /dev/mapper no Linux.
Vamos checar se esse dispositivo é um disco ASM:
/oracle/app/193/grid/bin/kfed read /dev/mapper/3600a098038304741475d4c4671542f49p1 |grep ‘kfdhdb.dskname\|kfdhdb.grpname\|kfdhdb.hdrsts’
kfdhdb.hdrsts: 3 ; 0x027: KFDHDR_MEMBER
kfdhdb.dskname: OBP_DATA_0007 ; 0x028: length=13
kfdhdb.grpname: OBP_DATA_NEW ; 0x048: length=12
Beleza, é um disco ASM: OBP_DATA_0007 (kfdhdb.dskname) e é membro (kfdhdb.hdrsts: KFDHDR_MEMBER) de um diskgroup ASM (kfdhdb.grpname): OBP_DATA_NEW.
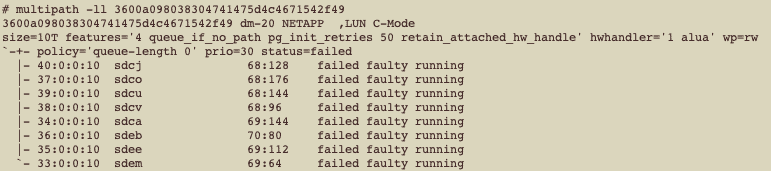
Vamos checar agora o status de multipath para esse disco:
multipath -ll 3600a098038304741475d4c4671542f49
600a098038304741475d4c4671542f49 dm-20 NETAPP ,LUN C-Mode
size=10T features=’4 queue_if_no_path pg_init_retries 50 retain_attached_hw_handle’ hwhandler=’1 alua’ wp=rw
`-+- policy=’queue-length 0′ prio=30 status=failed
|- 40:0:0:10 sdcj 68:128 failed faulty running
|- 37:0:0:10 sdco 68:176 failed faulty running
|- 39:0:0:10 sdcu 68:144 failed faulty running
|- 38:0:0:10 sdcv 68:96 failed faulty running
|- 34:0:0:10 sdca 69:144 failed faulty running
|- 36:0:0:10 sdeb 70:80 failed faulty running
|- 35:0:0:10 sdee 69:112 failed faulty running
`- 33:0:0:10 sdem 69:64 failed faulty running
Hummm, interessante, não? Todos os paths estão sendo marcados com falha.
Essa situação não é comum e geralmente acontece quando nós temos problemas na SAN (portanto, poderia ser o storage, storage controllers, switches de rede, HBAs). Mas, o interessante é que apenas uma ÚNICA LUN que está sendo reportada com falha. Se nós tivéssemos problemas na SAN, muito provavelmente nós teríamos TODAS as LUNs sendo reportadas com falha.
Isso estava deixando todo mundo “doido”! 🙂
Checando no site de suporte da Red Hat, eu encontrei a seguinte nota:
Para acessar esse link, você precisa ter um contrato de suporte ativo com a Red Hat.
Para deixar as coisas fáceis de serem entendidas, eu vou colocar um pequeno pedaço da nota de suporte aqui. Observe que a nota é bastante detalhada e possui bastante informação. Abaixo, apenas um pequeno pedaço:
Root Cause
Storage is notifying the host that a change within the storage configuration (mapping/presentation/masking of luns) has occurred. For example, storage added new luns (benign), unmapped and removed luns not currently in use (benign), unmapped and removed luns currently in use (data loss), or swapped luns (data corruption likely).
Resolution
Discuss and review the changes with your storage admin to determine how to proceed.
Note: if no changes have happened within storage, engage the storage vendor to determine why this hardware status is being returned. The kernel only logs this event returned from storage. The kernel does not have any further insight into why storage is returning this status event to the host.
Portanto, resumindo uma das possíveis causas-raiz:
- Essa é uma notificação do storage sobre alguma mudança na LUN some change on LUN (mapping, presentation, masking).
Sobre a resolução, isso é interessante:
- O kernel apenas mostra os eventos que são retornados do storage.
Portanto, a mensagem “Warning! Received an indication that the LUN assignments on this target have changed.” é exibida no /var/log/messages, mas, basicamente, é por conta de um evento retornado do storage.
Como estávamos tendo esse problema em tempo-real, nós conseguimos abrir um ticket com o vendor (NetApp) e tivemos o suporte de um engenheiro de suporte para discutir conosco sobre o problema, e, felizmente, nós conseguimos identificar (e entender) o porque enfrentamos esse problema.
Esse é um ambiente de PreProd. Nós fizemos um refresh desse ambiente há alguns meses através da clonagem dos discos de Produção. Essa é uma tarefa que é executada comumente no cliente usando a mesma abordagem de clonagem e eles nunca enfrentaram problemas.
Como citado no blog post anterior, numa solução de storage, você pode ter arrays de disco, os quais nós chamamos de “aggregate”. Nesse cliente, eles possuem alguns aggregates. A LUN que foi clonada de Produção estava sendo armazenada num aggregate AFF. Isso significa “All Flash FAS”, e é um aggregate que possui exclusivamente SSDs. O cliente estava com um problema de limitação de espaço nesse aggregate e desejava mover as LUNs de PreProd para o aggregate FAS. FAS significa Fabric-Attached-Storage”, o que é basicamente um array composto por discos híbridos, entre SSD e Hard Disk Drives.
Portanto, basicamente, eles moveriam a LUN (para o DISK7) do aggregate AFF para o aggregate FAS.
Quando o time de storage do cliente explicou que estavam movendo a LUN para outro aggregate, o engenheiro da NetApp pediu para o time de storage algumas informações. Por sorte, o time de storage salvou as informações antes de iniciar o move da LUN.
O comando abaixo foi executado na console do storage (NetApp), e, pode não funcionar dependendo da sua versão de Sistema Operational no seu storage NetApp. Observe que se você utiliza outros fabricantes de storage, o conceito provavelmente seja o mesmo, mas os comandos serão totalmente diferentes:
lun mapping show -path /vol/dbnode1_data_new_007_ref2023/DATA7 -vserver CA-PREPROD-SVM -igroup dbnode1_ig
Vserver Name: CA-PREPROD-SVM
LUN Path: /vol/dbnode1_data_new_007_ref2023/DATA7
Volume Name: node1_data_new_007_ref2023
Qtree Name: “”
LUN Name: DATA7
Igroup Name: dbnode1_ig
Igroup OS Type: linux
Igroup Protocol Type: iscsi
LUN ID: 10
Portset Binding Igroup: –
ALUA: true
Initiators: iqn.1994-05.com.redhat:a916a5e59b8c
LUN Node: CA-AFF1-B
Reporting Nodes: CA-AFF1-A, CA-AFF1-B
Perfeito, podemos ver que a LUN DATA7 está no nó de storage CA-AFF1-B (como listado no campo LUN Node).
Nós também podemos ver que havia dois “Reporting Nodes” para essa LUN: CA-AFF1-A e CA-AFF1-B.
Perfeito! Vamos ver agora os detalhes da LUN após ela ser movida do aggregate FAS para o aggregate FAS:
lun mapping show -path /vol/dbnode1_data_new_007_ref2023/DATA7 -vserver CA-PREPROD-SVM -igroup dbnode1_ig
Vserver Name: CA-PREPROD-SVM
LUN Path: /vol/dbnode1_data_new_007_ref2023/DATA7
Volume Name: dbnode1_data_new_007_ref2023
Qtree Name: “”
LUN Name: DATA7
Igroup Name: dbnode1_ig
Igroup OS Type: linux
Igroup Protocol Type: iscsi
LUN ID: 10
Portset Binding Igroup: –
ALUA: true
Initiators: iqn.1994-05.com.redhat:a916a5e59b8c
LUN Node: CA-FAS1-D
Reporting Nodes: CA-FAS1-C, CA-FAS1-D
Agora, podemos ver que a LUN DATA7 está no nó de storage CA-FAS1-D (como listado no campo LUN Node).
Nós também podemos observar que há dois “Reporting Nodes” para essa LUN: CA-FAS1-C e CA-FAS1-D.
OK, de acordo com o engenheiro da NetApp, a mensagem que recebemos inicialmente no sistema operacional: “Warning! Received an indication that the LUN assignments on this target have changed.”, aconteceu porque a LUN foi movida para outro nó do storage, mas, o nó para o qual ela foi movida (CA-FAS1-D) não estava listada como um Reporting Nodes field. Portanto, de acordo com o que ele disse, se você está planejando mover sua LUN para um nó que não é listado como Reporting Node, você deveria primeiro adicionar o nó que será o alvo do move como um Reporting Node. Portanto, na console do storage:
lun mapping add-reporting-nodes -vserver CA-PREPROD-SVM -path /vol/dbnode1_data_new_007_ref2023/DATA7 -igroup dbnode1_ig -nodes CA-FAS1-C CA-FAS1-D
Depois disso, no servidor de banco de dados (no Linux), execute o seguinte:
/usr/bin/rescan-scsi-bus.sh –a
Portanto, se o time de storage tivesse adicionado os nós alvo (os que estão no aggregate FAS) e o time de Linux tivesse rescaneado os devices no servidor de banco de dados, mesmo mend a LUN para o aggregate FAS, nós não teríamos enfrentado esse problema do disco ficar indisponível no sistema operacional.
Por favor, observe que os comandos listados acima e executados na console do storage estão aqui apenas como informação. Se um cenário semelhante acontecer com você, você DEVE envolver o time de storage.
O procedimento para adicionar os reporting nodes está listado no artigo de KB da NetApp:
How Selective LUN Mapping (SLM) works
Para acessar esse KB você deve ter acesso ao site de suporte da NetApp.
Para tornar o entendimento fácil, eu vou colocar abaixo um pedaço do que está escrito no KB:
For mobility events that move the LUN from one HA pair to another, the two new commands LUN mapping add-reporting-nodes and LUN mapping remove-reporting-nodes, support changing the nodelist.
Para eventos de mobilidade onde haverá move de LUN de um par HA para outro par, os dois comandos para mapeamento de LUN (add-reporting-nodes e remove-reporting-nodes), suportam a alteração da lista de nós onde a LUN estará.
É isso!
Espero que esse post tenha sido útil!
Um abraço!
Vinicius


