Olá pessoal, espero que estejam bem!
Nesse blog post, vou discutir um pouco sobre DM Multipath e porque isso é tão importante quando estamos falando de banco de dados.
OK, primeiro vamos entender como os discos interagem com bancos de dados e/ou vice-versa.
Se você pensar à respeito de Bancos de Dados Relacionais, Banco de dados é basicamente uma coleção organizada de informações estruturadas, ou dados, tipicamente ARMAZENADOS eletronicamente num sistema computacional.
Vocês notaram a palavra destacada? ARMAZENADOS.
Sim, um banco de dados precisa ser armazenado em algum lugar para que possa ser acessado. Um banco de dados precisa ser armazenado num disco (ou conjunto de discos), dessa forma, você poderá ler ou escrever no seu banco de dados, o que basicamente são leituras/gravações físicas no(s) disco(s) onde seu banco de dados está armazenado.
OK, estou assumindo que se você está lendo meu blog, você já é um DBA, e obviamente, você sabe que seu BD Oracle está armazenado em discos.
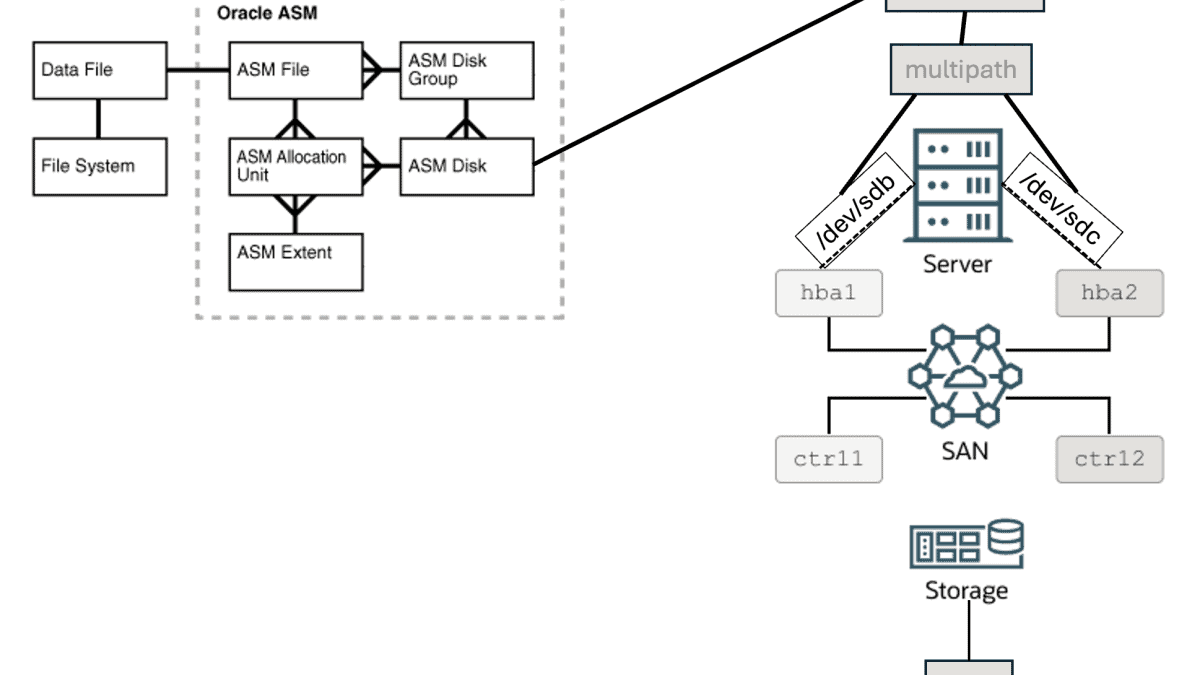
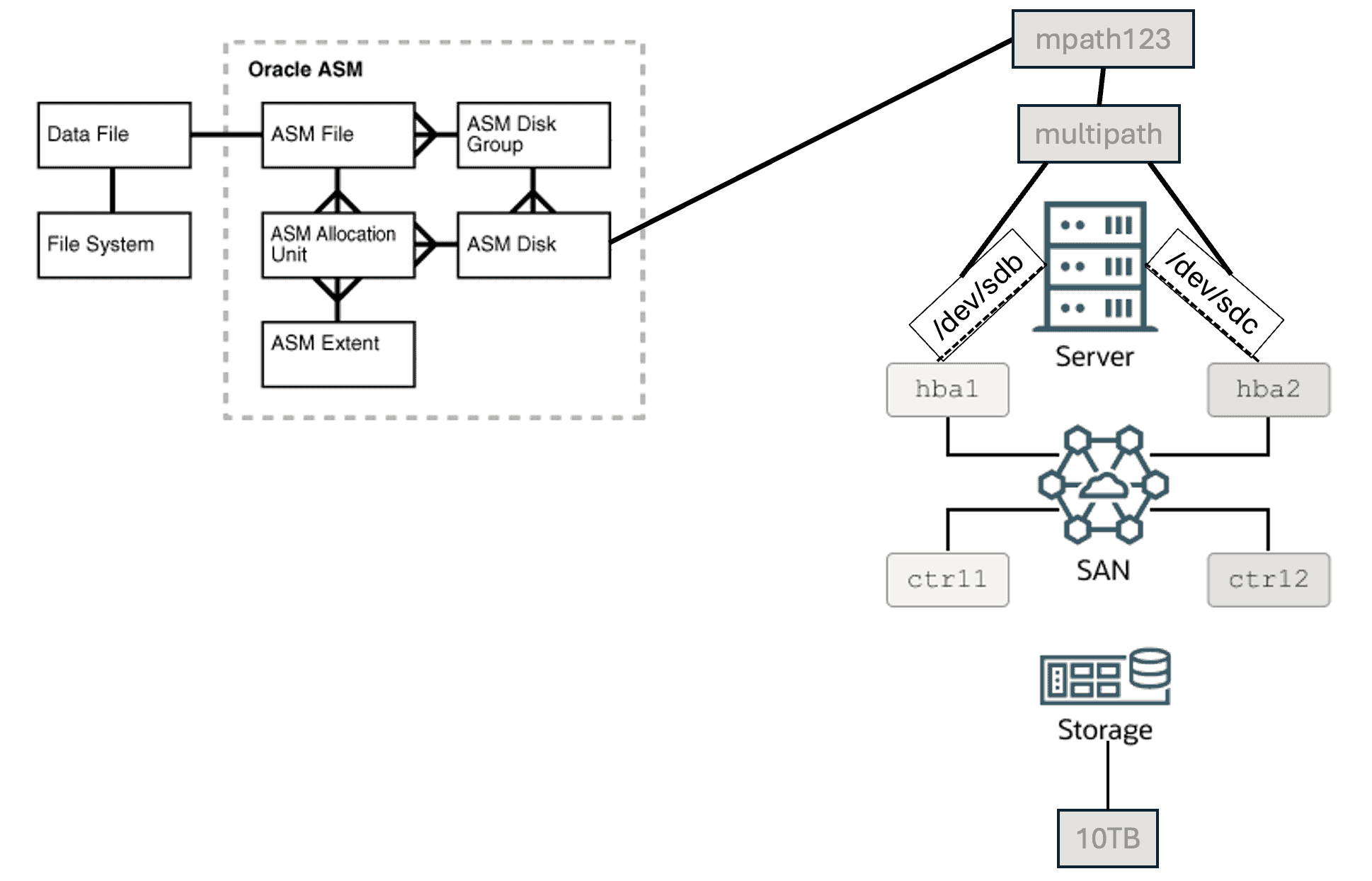
Abaixo temos uma figura que exemplifica de forma bem prática as estruturas físicas de armazenamento quando usamos Oracle ASM. A figura possui uma pequena alteração que fiz em relação à figura original.
Você pode ler sobre a imagem acima aqui:
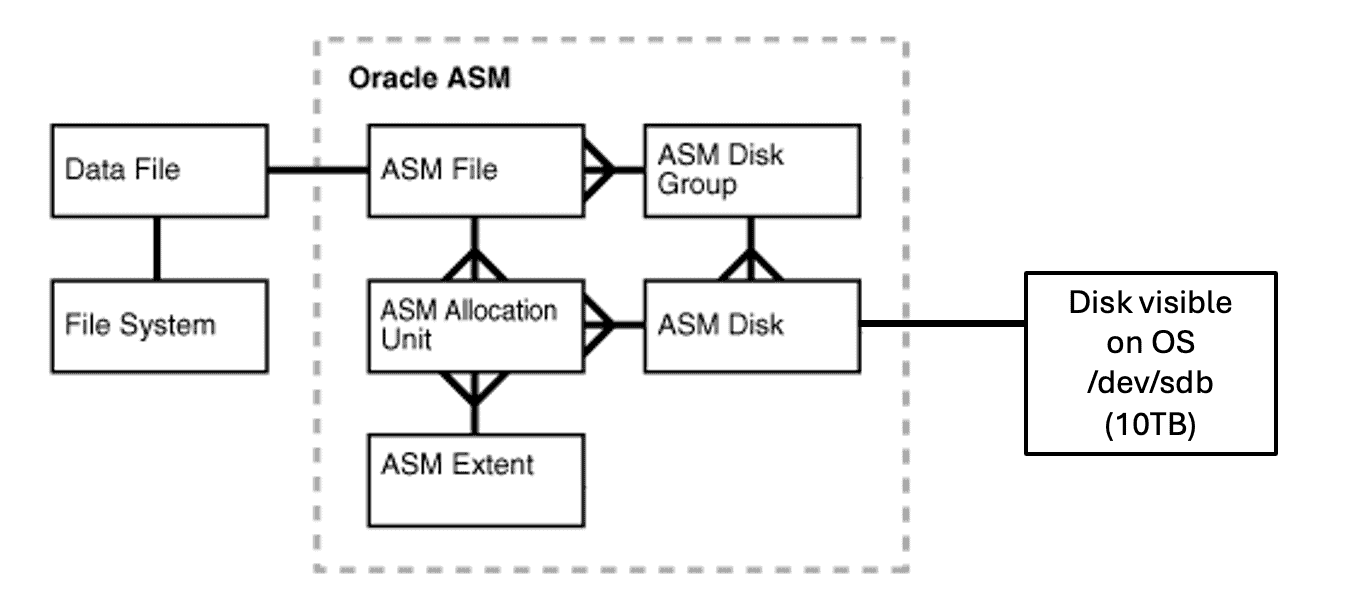
Portanto, na figura acima, você tem um disco ASM, que é visível no sistema operacional como /dev/sdb e possui 10TB de capacidade. OK, agora imagine que o disco exibido como /dev/sdb não é um disco local anexado/attachado ao servidor. Ao invés disso, é um disco que vem do storage.
Vamos ver agora, de maneira superficial, como o disco é apresentado do storage para o servidor de banco de dados.
Um storage é uma solução que funciona de maneira crucial para armazenar, gerenciar e proteger os dados. Basicamente é um sistema composto por um conjunto de discos (e que podem ser de vários tipos de discos: Hard Disk Drives (HDDs), Solid-State Drives (SSDs), Discos Híbridos (combinados entre SSD e HDD), Enterprise SAS/SATA SSDs, NVMe SSDs, etc), storage controllers (que gerenciam os discos e ajuda na comunicação entre o sistema de storage e os dispositivos que o acessam), storage enclosure (onde os discos são colocados e que fornecem uma proteção física aos discos, além de conectividade aos mesmos), infraestrutura de rede de storage (como o storage se conecta aos outros servidores: Fibre Channel, iSCSI, etc), software do storage (o software que gerencia todas as funcionalidades do storage: gerenciamento de dados, proteção, snapshot, replicação, deduplicação, etc), recursos de redundância e alta-disponibilidade (geralmente um storage possui recursos como RAID, espelhamento, clusterização, para garantir disponibilidade de dados e proteção contra falhas de hardware), além de outros componentes.
Portanto, num sistema de storage, podemos ter muito espaço disponível (muitas vezes na faixa de exabytes de capacidade).
O storage geralmente é conectado à uma rede (lembre do componente de infraestrutura de rede storage citada acima), nós chamamos isso de SAN (Storage Area Network). Essa é uma arquitetura de rede especializada que permite que múltiplos servidores ou hosts acessem de maneira eficiente e centralizada o storage que possui recursos compartilhados. Num ambiente SAN, os dispositivos de storage como disk arrays, são conectados a uma infraestrutura dedicada de rede, permitindo que os servidores acessem os recursos de storage que são permitidos para esses determinados dispositivos/hosts como se eles estiverem localmente anexados/attachados aos servidores. Portanto, quando você está trabalhando num ambiente SAN, é comum ouvir o termo “apresentar o disco ao servidor”, o que significa que você liberará acesso de alguma capacidade específica do storage (disco) para um servidor específico (ou conjunto de servidores).
Vamos pensar como os discos são “apresentados” do storage para os servidores de banco de dados. Imagine que possuímos um storage de 2 petabytes de capacidade, o que significa basicamente 2048 terabytes. Nós podemos por exemplo apresentar um disco de 10TB para um servidor de banco de dados. Eu poderia apresentar um único disco de 10TB do storage para o servidor de banco de dados, mas, usando um único disco nos coloca sob risco: e se o disco falhar? Se isso acontecer e o disco se tornar indisponível, nossos dados poderão ser perdidos. Nós temos que evitar isso.
Portanto, essa é a razão do storage possuir um array de discos (e vamos assumir aqui que nós possuímos todos os recursos/features de proteção devidamente configuradas). Dessa maneira, se nós apresentarmos um disco de 10TB do storage para o servidor de banco de dados, nós não apresentaremos um único disco, mas um pequeno pedaço do array de discos (lembrem: no nosso exemplo o storage possui 2 petabytes de capacidade e iremos apresentar apenas 10TB para o servidor de BD). Esse pequeno pedaço é geralmente chamado de LUN (Logic Unit Number). Essencialmente, uma LUN é um pedaço da capacidade do sistema de storage que está disponível para um host (servidor de BD) para objetivos de armazenamento, nesse caso, para ser usado como um disco ASM.
Um storage também pode ter mais de um storage controller (para fins de redundância). Vamos imaginar que nosso storage possui dois storage controllers. Vamos também imaginar que nosso servidor de BD possui duas HBAs (Host Bus Adapter). HBA é um componente de hardware usado em ambientes SAN para conectar servidores à dispositivos de storage, como por exemplo, arrays de disco. Geralmente, um servidor de BD possui múltiplos HBAs, novamente, para redundância.
No cenário abaixo, vamos assumir que estamos usando um sistema Linux (RHEL/OEL).
Com isso dito, vamos imaginar que iremos apresentar uma LUN de 10TB para um servidor de banco de dados. Vamos imaginar que nossa SAN possui 2 controladoras e nosso servidor de banco de dados possui 2 HBAs.
Isso significa que uma única LUN de 10TB pode ser reconhecida como “dois (ou mais) diferentes discos” à partir do Linux. Portanto, nossa LUN de 10TB pode ser reconhecida como /dev/sdb e /dev/sdc no sistema operacional. Cada “disco” reconhecido no sistema operacional, nós chamamos de “path”. Vamos olhar a imagem abaixo:
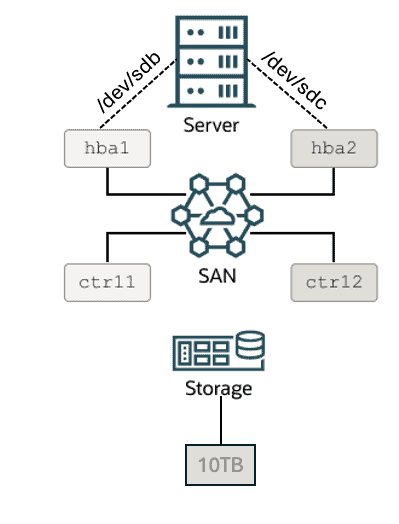
OK, vamos juntar agora as duas figuras em uma só:
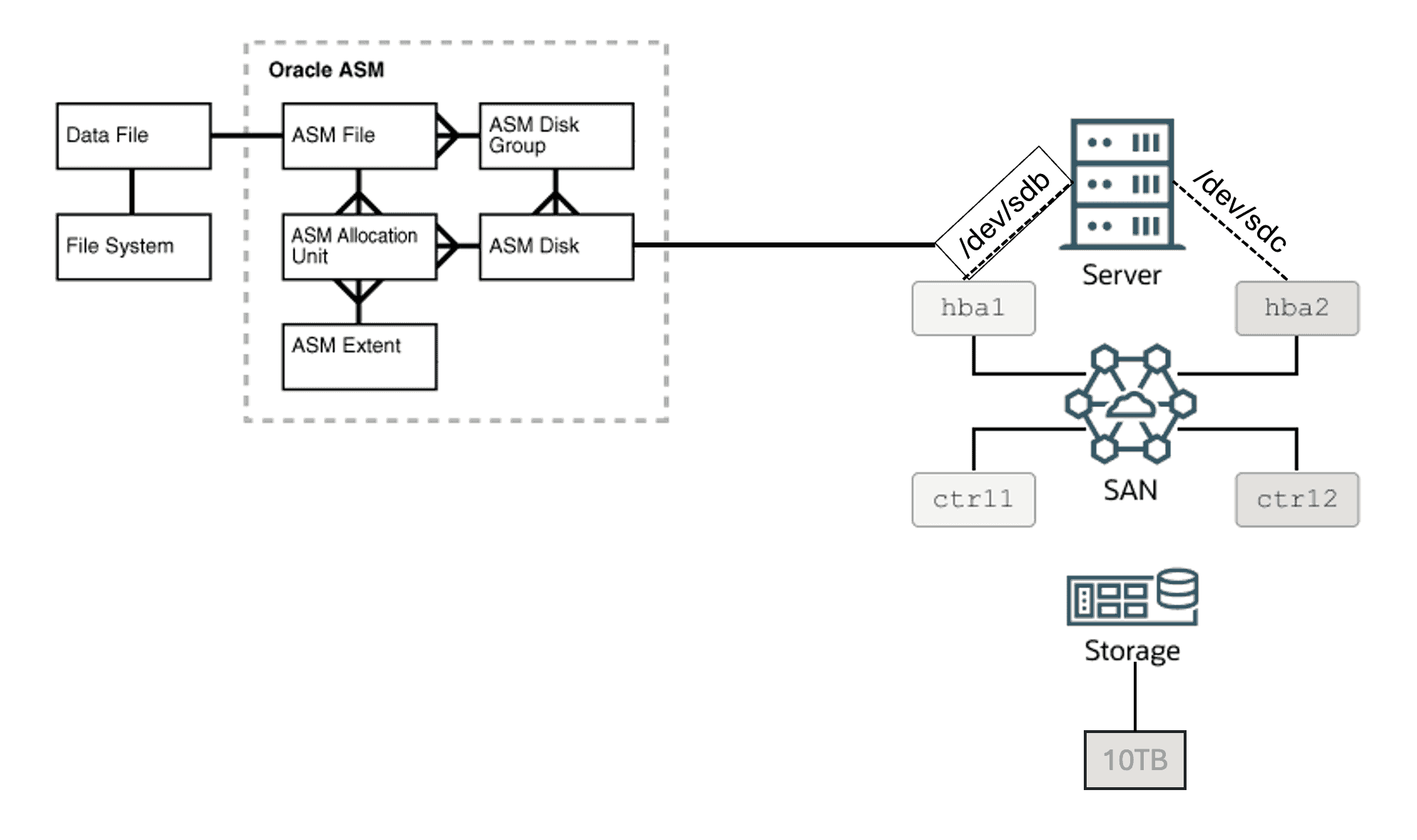
Eu posso usar o /dev/sdb como path para o meu disco e usá-lo como um disco ASM, isso vai funcionar sem problemas. Mas vamos imaginar que por qualquer motivo, esse path falhe (talvez por conta de uma falha no storage controller, uma falha na fibra óptica, uma falha no HBA, etc). Se eu estiver usando o /dev/sdb e ele falhar, meu disco se tornará indisponível no BD mesmo que eu ainda possua o outro path disponível (/dev/sdc).
É aqui que o Device Mapper Multipath entra em ação. O DM Multipath é um componente de software em sistemas operacionais Linux para fornecer redundância de path para os dispositivos de storage, particularmente em SANs. Isso ajuda a melhorar a confiabilidade, disponibilidade e performance através da gerência/manutenção de múltiplos paths (ou rotas) entre os servidores e o storage. Portanto, nesse caso, nós receberemos a LUN de 10TB através de dois paths (/dev/sdb e /dev/sdc). Eu não devo usar um path individual, já que isso é reconhecido como um SPOF (Single Point of Failure – Ponto Único de Falha). Portanto, ao invés de usar o path individual, nós podemos configurar um componente de software que fornecerá redundância de path. Portanto, no nosso exemplo, se o Multipath está devidamente configurado, nossa LUN de TAB poderá ser acessada através de um dispositivo (por exemplo), mpath123, ao invés de /dev/sdb ou /dev/sdc.
Quando nós usamos Multipath, nós podemos ter diversos tipos de configuração: ativa/passiva, ativa/ativa, etc. Numa configuração ativa/passiva, os requests de I/O usam apenas um path. Se esse path falhar, o Multipath vai automaticamente fazer o switch para usar o outro path. Essa é a configuração default. Numa configuração ativa/ativa você pode potencialmente melhorar a performance em ambientes de storage, pois, usando múltiplos paths para transferir dados permitirá que você tenha um aumento de largura de banda, além disso, há também o balanceamento de carga entre os múltiplos path para otimizar a utilização de recursos. Observe que esse ganho de performance não está relacionado ao tempo de leitura/gravação do disco. Está basicamente relacionado à largura de banda entre storage e servidor de banco de dados.
Edit: Como eu disse antes, quando estamos usando Multipath, nós podemos ter dois ou mais paths. No nosso exemplo, se nós temos duas storage controllers e duas HBA’s, o número esperado de paths são 4 paths.
Abaixo uma imagem da documentação da Red Hat:

Você pode acessar e ler mais sobre a imagem acima aqui:
Agora você já percebeu porque é tão importante usar o Multipath, certo? Como DBA’s, nós temos que garantir que nossos bancos de dados estejam sempre disponíveis, escolher e configurar os components certos de maneira apropriada são tão importantes quanto ter um BD bem administrado.
Importante dizer que o DM Multipath é uma solução de software nativa do Linux. Dependendo da sua solução de storage, você poderá usar soluções de Multipath específicas do vendor do storage (algumas vezes tendo que pagar por alguma licença para usar):
- EMC PowerPath;
- NetApp Multipath I/O (MPIO);
- IBM MPIO for AIX;
- Many others.
Quando você está usando ASM, discos ASM podem ser configurados usando udev, ASMLib ou AFD em sistemas Linux. Preste atenção em garantir que você usará Multipath na configuração do seu disco ASM.
Vamos assumir que os dispositivos de Multipath são listados como 3600* embaixo do caminho /dev/mapper.
Para o AFD, você deve configurar dessa maneira:
cat /etc/afd.conf
afd_diskstring=’/dev/mapper/3600*
afd_filtering=enable
Para o ASMLib:
O arquivo /etc/sysconfiug/oracleasm é um link simbólico que aponta para o arquivo /etc/sysconfig/oracleasm-_dev_oracleasm:
oracleasm -> /etc/sysconfig/oracleasm-_dev_oracleasm
Eu vou mostrar apenas a parte que mostra a configuração para os dispositivos de multipath:
cat /etc/sysconfig/oracleasm-_dev_oracleasm
# ORACLEASM_SCANORDER: Matching patterns to order disk scanning
ORACLEASM_SCANORDER=”dm”
# ORACLEASM_SCANEXCLUDE: Matching patterns to exclude disks from scan
ORACLEASM_SCANEXCLUDE=”sd”
Para o UDEV, dependerá bastante da sua distribuição Linux e versão usada, por exemplo:
How To Setup Partitioned Linux Block Devices Using UDEV (Non-ASMLIB) And Assign Them To ASM? (Doc ID 1528148.1)
cat /etc/udev/rules.d/99-oracle-asmdevices.rules
KERNEL==”xv*”, BUS==”scsi”, PROGRAM==”/sbin/scsi_id -g -u -s %p”, RESULT==”360a98000375331796a3f434a55354474″, NAME=”asmdisk1_udev_p1″, ACTION==”add|change”, OWNER=”grid”, GROUP=”asmadmin”, MODE=”0660″
Espero que esse blog post tenha sido útil para você.
No próximo blog post eu vou mostrar como nós passamos por um problema mesmo com o Multipath devidamente configurado.
Um abraço!
Vinicius


