Olá pessoal, Espero que estejam bem! No meu último blog post eu mostrei como fazer o update do Oracle Enterprise Manager e seus OEM Agents do RU 13.5.0.16 para o RU 13.5.0.20. Você pode ver aqui: Como atualizar o Oracle Enterprise Manager do RU 13.5.0.16…
Olá pessoal, Espero que estejam bem! Um cliente nos contatou solicitando que atualizássemos o seu ambiente de Oracle Enterprise Manager e os agentes do 13.5.0.16 para a última release disponível. Primeiro de tudo, nós precisamos entender de qual nota de suporte nós podemos encontrar o…
Olá pessoal, Espero que estejam bem! Nas últimas semanas, eu publiquei dois blog posts sobre atualização do servidor de banco de dados do RHEL 7 para o RHEL 8. No meu último blog post, eu descrevi como corrigir um erro/bug que está relacionado aos módulos…
Olá pessoal, Espero que estejam bem! No meu último blog eu escrevi sobre um problema com os módulos do ACFS depois de uma atualização do Sistema Operacional para o RHEL 8.8. Bem, se você leu esse blog post que eu cito, você sabe que se…
Olá pessoal, Espero que estejam bem! Um cliente me ligou porque eles encontraram problemas enquanto estavam atualizando o sistema operacional do RHEL 7.9 para o RHEL 8.8. Observe que RHEL significa Red Hat Enterprise Linux. O ambiente é composto por clusters rodando no 19c. Eles…
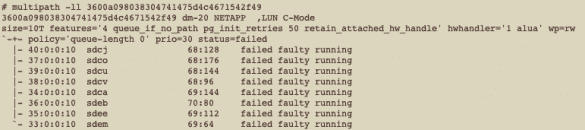
Olá pessoal, espero que estejam bem. No meu último post, expliquei um pouco os conceitos sobre Multipath e a importância de usá-lo. Você pode ler o post aqui: Device Mapper Multipath – Como isso funciona? Porque como DBA eu preciso me preocupar com isso? No…
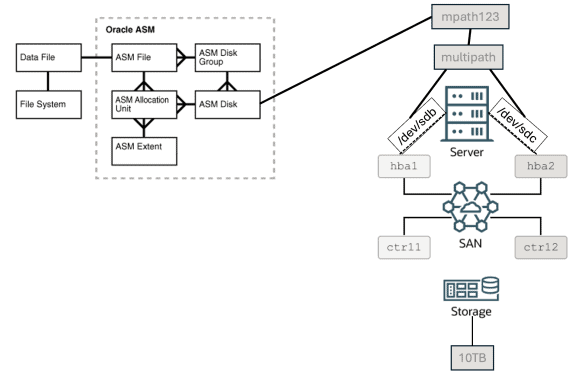
Olá pessoal, espero que estejam bem! Nesse blog post, vou discutir um pouco sobre DM Multipath e porque isso é tão importante quando estamos falando de banco de dados. OK, primeiro vamos entender como os discos interagem com bancos de dados e/ou vice-versa. Se você…
Olá pessoal, Espero que estejam bem. Estava trabalhando para um cliente onde eles possuem um ambiente DR rodando com o ActiveDataGuard, ou seja, um banco de dados standby físico aberto em modo somente leitura (read only mode) enquanto as transações geradas em Produção são aplicadas…